AURENA Tech strengthens its QA team
Anatolii Vynarchuk joins AURENA Tech to expand our Quality Assurance team.
05.01.2022
written by David Dawson
I recently stumbled across an interesting discussion article by @BenLugavere, “You’re not going to replay your event stream”, from back in 2018.
It’s an interesting read to spawn a discussion from, I recommend you have a look, I’ll wait … I don’t know Ben, however he did invite a discussion on his article, so I will discuss it, as the subject is fairly timeless.
Although, I’m sure he didn’t imagine I would do it years later, but I’ve been away, meh
So, I love my event systems, I am primarily building event systems for my 2 main current clients, and I’ve been designing and building them for years.
Ben makes some good points around event architectures, particularly on the maintenance burden and issues distributing schema migrations across systems that have to deal with historical versions. I can totally agree with Ben here:
This can result in verbose forks in the code where both [current and historical code paths] need to be maintained.
Ben Lugavere
I can feel his pain in this, a lot of what’s need to successfully implement these concepts is not obvious.
There is, however, a merging of concepts that underlies his points, in that several different concepts have collided in his examples. One that I’ve found to be particularly common when building event based systems and components.
You see, what is appearing in his article is actually a mix of three things, one is Event Sourcing of an Aggregate Root, the others are stateful and stateless event based stream processing.
This is the issue he’s struggling with, and is actually why he’s shying away from the concept of Event Sourcing, as how it’s appearing in his system has stateful replay problems.
This sort of collision of concepts is remarkably common, and seems to be one of the reasons that event architectures aren’t as often adopted as I think they perhaps could be.
So, what’s the difference? How could his example be reworked, does it help?
Can event streams be safely replayed in any event sourced system?
I’ve been working with a great team over the last year at Aurena. They mostly have a JavaScript background, much of it from the direction of the browser.
My first love in tech was the Java Virtual Machine. No matter your opinion, I think it’s a lovely technology and ecosystem. It is, though, a particularly different runtime from anything JavaScript related.
Much of the thinking around the application of Domain Driven Design (DDD), and Event Sourcing that grew out of it was done in the .NET, and then the Java worlds. Both of those world views are suited to thinking in terms of classes, objects, threads and long term persistent state in the form of the Domain Object.
Coming from the JavaScript/ UI world, this domain object concept just doesn’t exist.
Redux is a prime example of this. It seems to have all of the event primitives, Sagas, events, views and so on.
It’s so close to what I would build in a server side event system … but it’s only similar.
It was intended to solve a different problem, and all the front end state containers follow similar patterns, as they are solving similar problems. However, even with all this functionality, there is something important about Redux.
It’s worth noting at this point that the Event Sourcing in Martin Fowlers article from 2005, while seminal in bringing the idea to a wider audience, does not quite describe what Event Sourcing really became. It appears in his abstract system diagrams that you would create a single transaction log for the entirety of the system that you can then recreate from, but that’s not how successful event sourcing is applied in practice. Martin even tackles the global replay problem by discussing idempotency gateways. Overall, it was an excellent write up of the state of the art thinking, in 2005, but much has changed since then. A lot of the concepts in the article have fallen by the wayside, and we now use others instead.
Why is this important? Well, to go back to Redux as an examplar of Event Sourcing …
It doesn’t even try to implement Event Sourcing.
To grasp why we need to define what Event Sourcing actually is.
In DDD, there is the concept of the Aggregate Root. This is a group of related domain object instances, that are loaded and persisted as a single transactional unit.
In many approaches to implementing DDD, changes to the Aggregate Root can be captured as a delta, a data structure describing the change. Then, these deltas are distributed around the rest of the system, these are referred to as Domain Events.
So far, so good. No Event Sourcing found here yet … even though we have events in the system already.
Now, the inspired thought that way back when was to implement the save and load of the Aggregate Root as a list of deltas describing the history of the instance.
When you make a change, you record the change as an event. The key piece, you only save the history, only the list of events.
Loading the Aggregate instance is then done by loading the event history for that instance, and passing it through the Aggregate Root reducer function to generate the current state. Altering the reducer will alter the representation of the current state, but will not alter the actual state which is in the form of the immutable event history.
The important pieces of machinery here are the load and save of a list of events, and a reducer function to generate a single instance.
The domain events? Nothing changes. They are still emitted, and they may be the same events that are inside the Aggregate history (some argue you don’t reuse them, every system I’ve built has done and not had any awful happenings beyond the odd implementation detail slipping out)
Outside of the Aggregate Root, you shouldn’t be able to tell if any component is event sourced or not. The fact that it’s pinging events out into the system only means that it’s pinging events into the system.
The most important thing here is that event Sourcing is always applied on a single instance of an Aggregate Root.
Redux doesn’t implement event sourcing, it mostly implements stream processing and different forms of event driven workflows. The actual domain objects that generate the events in an event sourced system mostly don’t exist in the world of redux.
In Bens example, he has a valid domain object, but it has blended in external state change with the internal implementation of AR persistence, Event Sourcing.
An event sourced Aggregate Root will fully replay every time it is loaded.
Here’s an example of a true Event Sourced Aggregate Root. Actual persistence is out of scope, but its simply taking the history property and saving it somewhere. The Aggregate instance initialises itself
interface AREvent {
eventType: string
value: any
}
class User {
_email: string
_name: string
constructor(readonly history: AREvent[]) {
history.forEach(event => this.apply(event))
}
private apply(event: AREvent) {
// this is the reducer thet implements the event folding
switch(event.eventType) {
case "EMAIL_SET":
this._email = event.value
break;
case "NAME_SET":
this._name = event.value
}
}
set email(value: string) {
const ev = {
eventType: "EMAIL_SET", value
}
this.history.push(ev)
this.apply(ev)
}
set name(value: string) {
const ev = {
eventType: "NAME_SET", value
}
this.history.push(ev)
this.apply(ev)
}
get name() {
return this._name
}
get email() {
return this._email
}
}
let user = new User([])
user.email = "[email protected]"
let user2 = new User(user.history)
console.log(user.history)
// [ { eventType: 'EMAIL_SET', value: '[email protected]' } ]
console.log(user2)
// User {
// history: [ { eventType: 'EMAIL_SET', value: '[email protected]' } ],
// _email: '[email protected]'
// }
Notice that you can recreate the AR at any point via its history, and when I create “user2”, its performing a full replay in order to recreate the current state of the instance.
This is it, Event Sourcing is nothing more than this. The problem of how to send emails, is simply in a different part of the system, the Saga, or stateful event workflow.
This is a concept that Redux and friends has, and the implementation is actually fairly good, however in all of the systems, there is very little visibility of the stream of events that are fed into the event processors. In most cases, they aren’t even referred to in that way, and so you miss that event stream appear in multiple places in any event system. Even though they could be hidden from you, they are there.
To see that in action, we need to start emitting these events to the rest of the system. To take the raw events gifted by Event Sourcing and start to build an actual event based system architecture.
To update the example above, you can capture events coming from the User aggregate like this:
class User {
_email: string
newEvents: AREvent[] = [] // capture of events that happened after the AR was initialised.
constructor(readonly history: AREvent[]) {
history.forEach(event => this.apply(event))
}
private apply(event: AREvent) {
// this is the reducer thet implements the event folding
switch(event.eventType) {
case "EMAIL_SET":
this._email = event.value
break;
}
}
set email(value: string) {
const ev = {
eventType: "EMAIL_SET", value
}
this.history.push(ev)
this.newEvents.push(ev)
this.apply(ev)
}
get email() {
return this._email
}
}
let user = new User([])
user.email = "[email protected]"
let user2 = new User(user.history)
user2.email = "[email protected]"
console.log(user2)
..
User {
history: [
{ eventType: 'EMAIL_SET', value: '[email protected]' },
{ eventType: 'EMAIL_SET', value: '[email protected]' }
],
newEvents: [ { eventType: 'EMAIL_SET', value: '[email protected]' } ],
_email: '[email protected]'
}
Here, you can see that the “newEvents” property is now capturing changes that have happened since the instance was loaded from persistence. At this point, we leave Event Sourcing behind, and step into the world of Domain Events.
To use these new events from a single aggregate, we combine them up into a single event stream for the entire User AR, for all the instances, and then provide that to the system as a combined stream. How that occurs really depends on your technical infrastructure, but I’ve found Kafka, Redis Streams and systems that implement a similar Event Log architecture are by far the best fit.
For now, we’ll combine two pieces to give a flavour of how the system should look.
Before we do that though, we need to touch on the semantics of how events are being consumed in the system. Notice that the Event Sourcing above is done on demand, it’s a pull model. The data that is in persistence is used during the replay, no events generated after that will be included. I refer to this as a “cold” replay.
There are 2 other replay models that you will find in an event system, that I alluded to above with when I referred to stateless and stateful.
Both of these other models operate on the combined event stream from all Users, and then do something with those events.
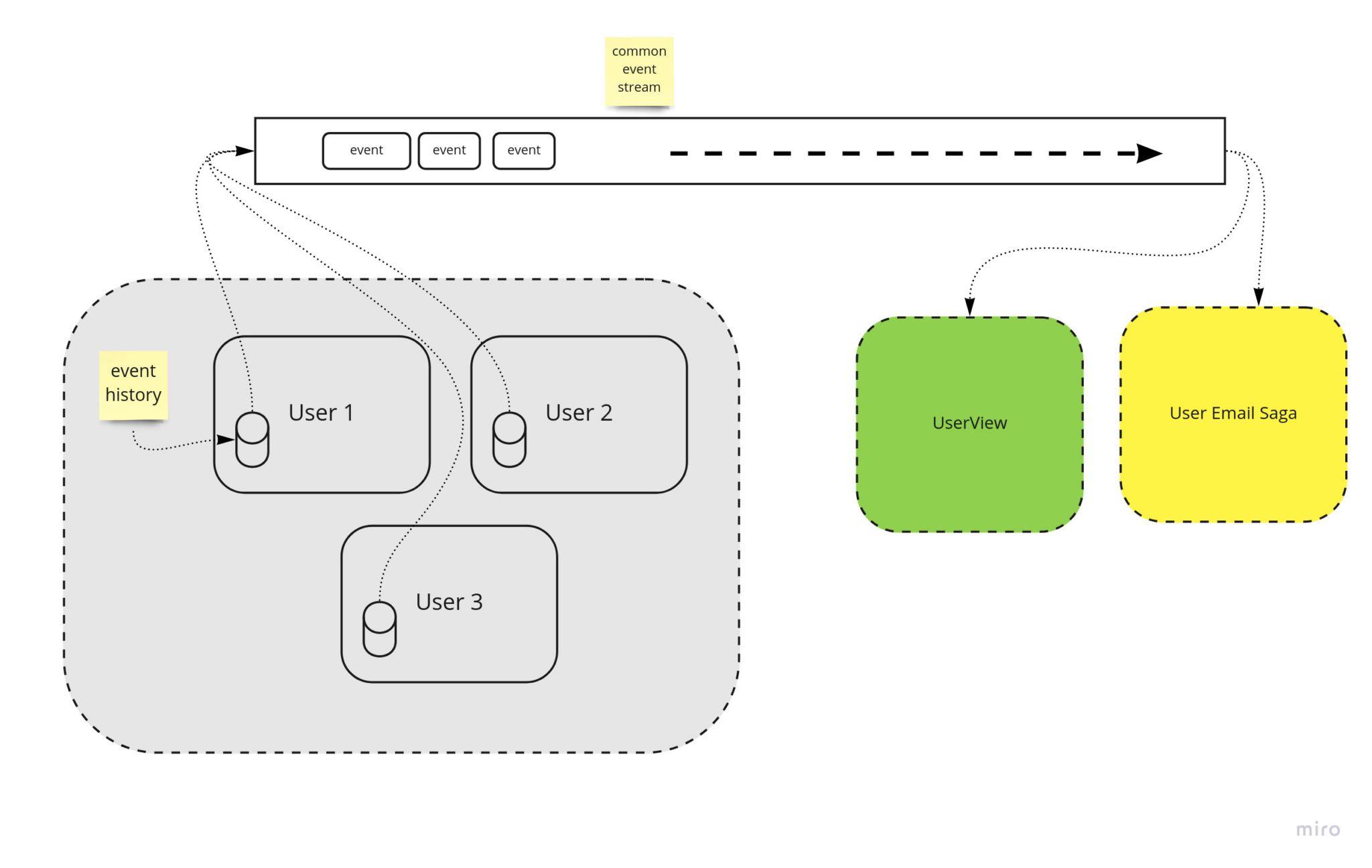
Generate events inside Aggregate Roots, put them onto a common event stream, process them in order at the end
They receive the events via a push, from the event stream.
This is the same concept you find the in the world of Reactive Programming, and if you look at the Marble Diagrams in there, you’ll see they contain the same ideas, a source, a sink, data flowing between them in order and being processed in some way.
The difference is one of emphasis, not implementation. DDD/ Event systems is defining what the components are, and what the semantics of the event stream between them is. Reactive is defining how you implement stream processing.
You use both together, The Why, and the How.
An Event driven View is a stateless reducer function that operates on the full, combined event stream. It will take events from all users, and generate some data structure that is optimised for a single job.
These views can be fully rebuilt from the event stream, if you have it, as they are a stateless function. They are generally what I refer to as “cold + hot” components, meaning that they replay from the start of the stream and then are constantly updating with new data as it appears.
They never complete processing, in the way that an event source load function will.
You can query the current state at a point in time. These are often replayed to alter the structure of the view. Although often its easier to just create a new view of the right shape and cutover.
Here’s an example of what a view could look like. Its really just a reducer with associated data structure at heart, so could be functional, RxJS or some other implementation. To make the code less dense, I’ve implemented it as a class with the the reducer current state as an instance variable, but that makes no different to its conceptual base.
The hard bit here is the semantics of the subscribeToColdHotEvents function. When mapped onto Kafka/ NE other, its just a consumer group with the offset set initially to 0.
class UserEmailsView {
emails: string[]
on(event: AREvent) {
if (event.eventType === "EMAIL_SET") {
this.emails.push(event.value)
}
}
userExists(email: string) {
return this.emails.includes(email)
}
}
let user = new User([])
user.email = "[email protected]"
emitEvents("users", user.newEvents)
let view = new UserEmailsView()
// this is hand waved, this needs to play all the existing events, then start pinging in hot ones
subscribeToColdHotEvents("users", view)
view.userExists("[email protected]") === true
view.userExists("[email protected]") === false
let user2 = new User(user.history)
user2.email = "[email protected]"
emitEvents("users", user2.newEvents)
view.userExists("[email protected]") === true
view.userExists("[email protected]") === true
Views are remarkably useful components. In most systems I’ve been involved with, there tends to be a single View for an entity to begin with, that just lets you do simple query and listing. Fairly soon though, teams realise they can have multiple views on the same data, and the event stream will ensure they remain consistent. This leads to the creation of highly optimised precalculated views on the data that can give huge performance improvements.
Now the the nub of the issue, stateful processing of event streams.
Side effects should be well contained in this sort of system, for all the issues that Ben points out in his article. They’re hard.
So, we put them in a box called “Saga”.
These also operate on the full event stream, but they do so in a stateful way.
The best comment I’ve heard on the nature of Sagas is this:
An Aggregate Root is a machine for taking commands and creating Events, A Saga is a machine for taking Events and creating Commands
We take an event, and then attempt to modify the state of the system in response to it, including by creating side effects out in the wide world.
When replaying parts of the system, it follows that we don’t want the side effects to happen again, and since we’re replaying, we don’t want the changes that a Saga will attempt to create via issuing Commands to re-occur.
Thus, Sagas are Never Replayed
In my taxonomy of the semantics of event stream processors, Sagas are a “hot” only component. They start up, and will process events that occur after they first came online, and never historical data.
Kafka and friends very much help here, as you can initialise a consumer group with the cursor at the current topic HEAD, which maps to this perfectly.
let user = new User([])
user.email = "[email protected]"
emitEvents("users", user.newEvents) // saga won't pick these up, no email, its historical
subscribeToHotEvents("users", (event) => {
// generate a side effect.
mailservice.send(event.value, "HEY THERE NEW PERSON")
})
let user2 = new User(user.history)
user2.email = "[email protected]"
emitEvents("users", user2.newEvents)
// [email protected] will get an email.
For those interested, this would be more properly called an Event Adapter, as its not performing a long running workflow. How they interact with the event stream is the same in both component types.
A more complex Saga implementation would take the events, issue commands and perform side effects and then store what has happened to the particular instances over time. How that is implemented can get pretty complex, and is out of the scope of this sort of write up.
So, we decomposed an app up into differing concerns. Did it help?
Well, we can safely replay the Aggregate Roots whenever they are loaded, which is nice. This means that we can add in new logic on top of the event data, as we aren’t tied to a fixed data representation. Compare to the original User, we can implement some new functionality that wouldn’t be possible otherwise. For example, say we want to prevent users re-using an email once they’ve used it. It would look like this:
class User {
previousEmails: string[] // We want to stop people re-using emails!
_email: string
newEvents: AREvent[] = []
constructor(readonly history: AREvent[]) {
history.forEach(event => this.apply(event))
}
private apply(event: AREvent) {
// No guard logic in a reducer, ever. The event has occurred, deal with it or ignore it for the purposes of replay, you do not reject them.
switch(event.eventType) {
case "EMAIL_SET":
this._email = event.value
break;
}
}
set email(value: string) {
// this is effectively a DDD Command handler. It operates before a change is made to the AR, and before the event is created, so it is the right place for guard logic to exist
if (this.previousEmails.includes(value)) {
throw new Error("You've used this before!")
}
const ev = {
eventType: "EMAIL_SET", value
}
this.history.push(ev)
this.newEvents.push(ev)
this.apply(ev)
}
get email() {
return this._email
}
}
let user = new User([])
user.email = "[email protected]"
user.email = "[email protected]"
user.email = "[email protected]" // ERROR
The important thing here, is that we can apply this change to a system that is already in prod, all the historical data exists to add this form of check on top of the existing underlying event sourced data.
Apart from this form of change, Event Sourcing gives you two things, one is a very convenient way to capture Domain Events, as I’ve shown. Again, some argue that internal events from an Aggregate Root aren’t the same as the externally distributed Domain Events, and I’m sure thats true in many cases. The more I build this type of system though, the more I think that’s more of an edge case than the main case. Every system I’ve built in this way has used the internal events from Event Sourced Aggregates as the source of Domain Events, even if sometimes we curated the ones that made it outside in some cases.
By doing this, you can then take those events and pipe them into some monitoring or observability system and use the event stream to give you an incredible wealth of data on the runtime operation and health of the application.
Here’s an example. I helped build a payment engine for AURENA Tech, it interacts with legacy systems via Kafka, and with the payment provider. API ops via GraphQL.
You are looking at the interplay of a variety of components across a set of complex distributed Sagas/ workflows. We piped the subsequent events (in Kafka in our case) into Elastic Search.
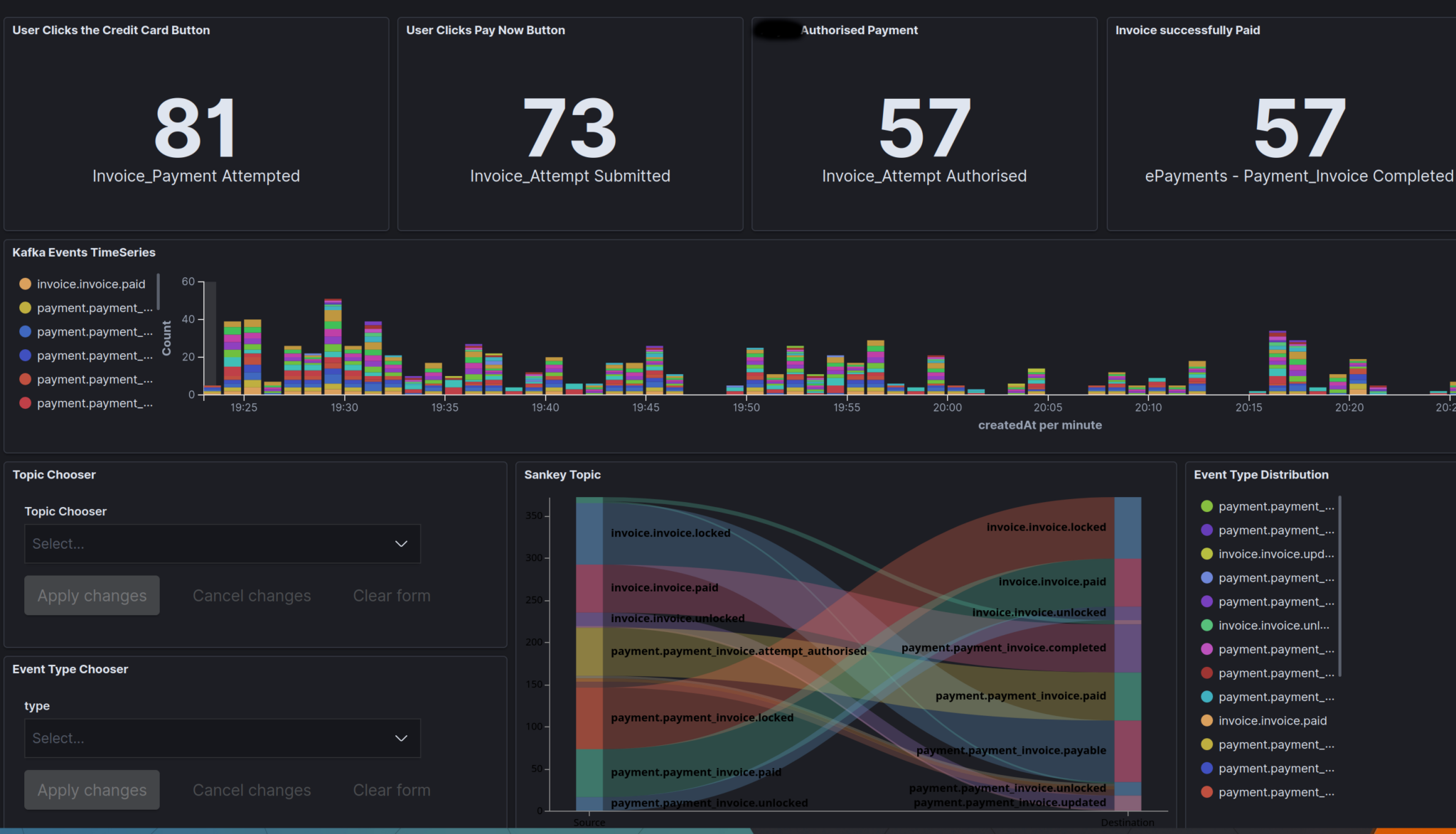
You can see the overall health of the system in the form of business KPIs, drawn directly from the domain events, that are drawn from our event sourced entities. I’ll emphasis the point, all the data above is only the raw events in the system, from our event based workflows. No massaging done.
The Sankey topic below is an interesting one, as it is showing causal information. That is, when an event was created, what caused it to be created? In most of these cases, its an event being processed by a Saga and then that Saga deciding to record its work via another Command/ Event emit. This is stamped as a “causedBy” on all our events, and has been useful in observing the complex interactions and identifying corner cases, especially when we get infrastructure failure.
The last thing that event sourcing is useful for, is debug. Ben is totally right that this is a benefit, but it should not be discounted just how useful this really is.
In the system above, we actually show the raw event stream for some of the entities in the UI. This is for the backoffice users, and gives them and us an easy way to understand the system operation, and know how and where to look when diagnosing distributed systems bugs (which almost always amount to an unforeseen race condition of some sort or another).
When building a distributed system, this class of bugs are a huge drain on your resources, and having ways to quickly grasp the nature of the race (rather than vague assertions that “it sometimes happens, but we’re not able to reproduce it”). Being able to take an existing event history and read it, find all the IDs, find the causal information and derive a distributed trace is magical in debugging.
It is also in the nature of distributed systems to be exposed to infrastructure failure and resource overload. This can be also be observed (apart from the normal manner) via the events, as you can see the relative emit vs receive vs process time of the events into the other components, leading to dashboards like this:
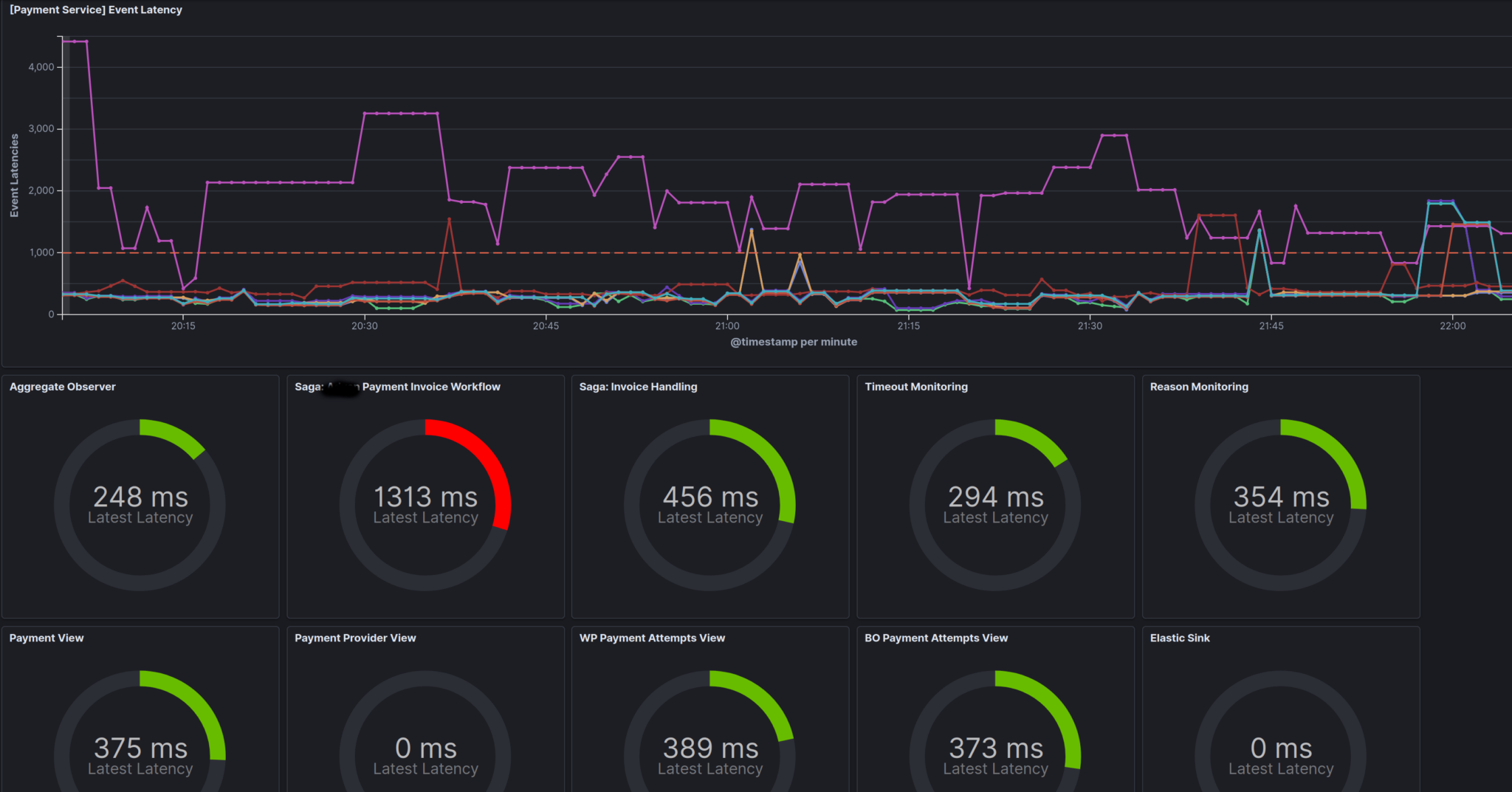
Here you can see the various event consumers and how long it is taking them to receive, and then process, events they are ingesting.
Elevated times here can point to which part of the system is struggling, and how. For example, long receive times indicate a Kafka issue, long process times, an issue with the DB, external integration or other resource contention.
All of this is made much, much easier by using Event Sourcing to bootstrap your system into a full distributed event architecture.
So, yes, I am very much in favour of building event sourced systems.