River and Racetrack: AURENA Tech Team Event 2026
Our team event 2026 took us to Styria for three days filled with outdoor challenges, international food and some serious racing action.
19.12.2022
written by David Dawson
Have you ever adopted a technology, only to have it do something that, if you’d thought about it, was easy to predict, but at the same time, awful to see actually happen?

Image: freepik.com
Say, a message queue that loses messages because its in memory only (hey fast!), or a database that loses data because it doesn’t flush to disk (it’s fast!)
Or… a well known API technology that rhymes with with “GraphQL” that encourages you to write deep graphs of objects that will very easily create circular dependencies. Which, if you build naively, will create a never ending graph of objects.. Or, at the very least, lead to the dreaded N+1 load problem.
Well, I’ve done all of those things, and this is how, with the AURENA team, we redesigned and built the AURENA GQL APIs to avoid it, leading to efficient, dynamic and easy to maintain GraphQL APIs.
We use NodeJS and Typescript as our primary development environment (other languages sometimes available). Since adopting GraphQL, we’ve used the Typegraphql project as the primary way of building GQL APIs in our microservices.
We’ve built using Apollo Server, and adopted Apollo Federation, which has worked out very well for us.
Together, these have been a nice environment for the team, I recommend you check out the projects.
As we’ve built more complex APIs, we’ve been running into the limits of our current approach to building these APIs.
As you start to design and build GraphQL, you can take different approaches. Since we’re building an event based system, we started by mapping out our processes as event workflows, identifying the commands, which will be the GQL Mutations. Then, identifying what queries we needed the external UIs to make, which are our GQL Queries. Finally, designing and building the internals to stitch all that together.
This worked, but the final step of implementing a whole query in one go led to some issues.
For part of our new system, we had to provide a GQL query that gives access to several entities related to what is called a “Distribution”. In this process, an Aurena employee (or agent) and a customer identify what they’ve bought and hand it over. This includes invoices, proofs, pictures and so on. Here is a simplified version of the model:
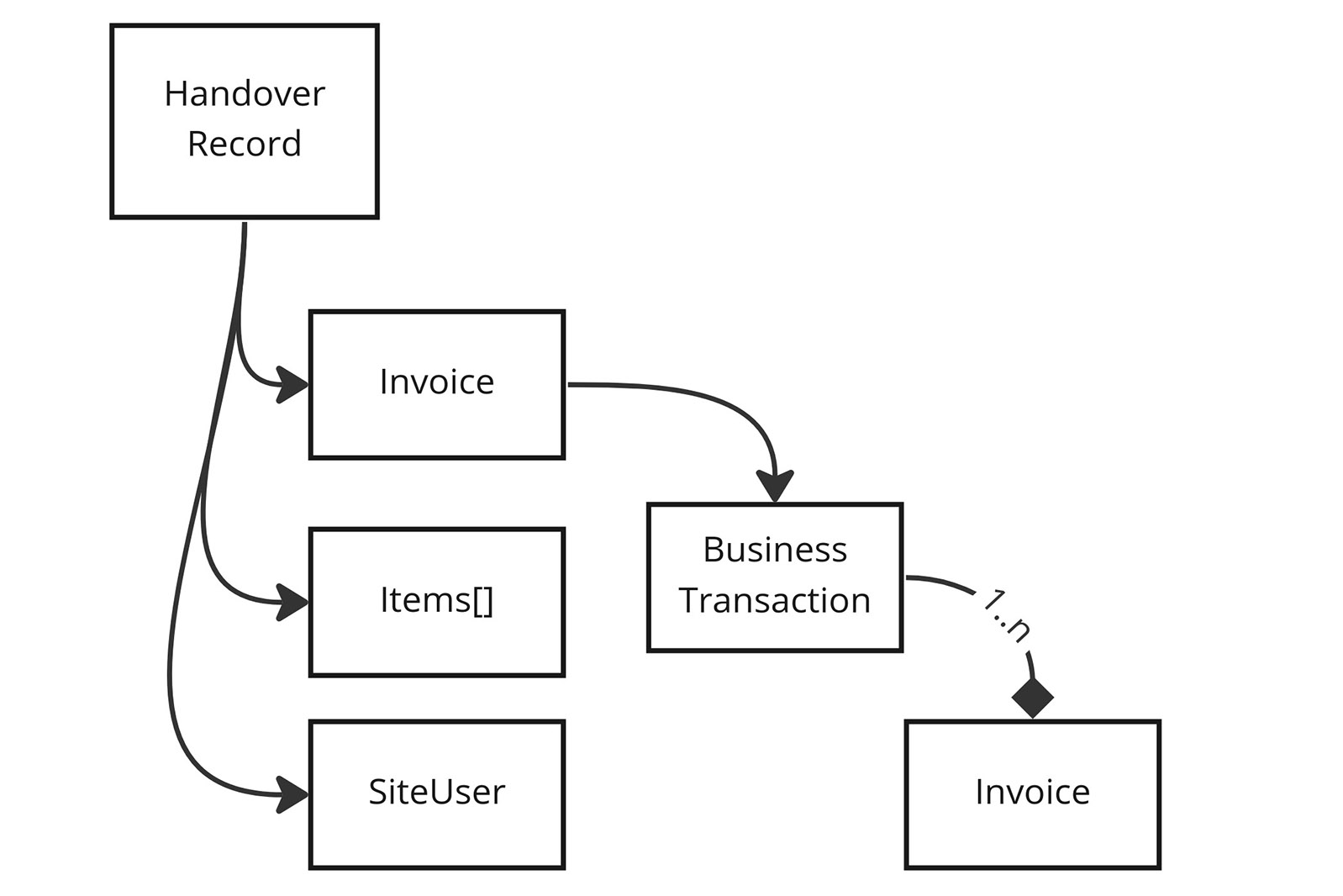
The GQL Query used to access it looks similar to this:
query getHandover($handoverId: ID!) {
handoverRecord(handoverId: $ID) {
id
invoice {
currency totalAmount tax
}
items {
id photoMain description locationRef
}
siteUser {
id email firstName lastName
}
businessTransaction {
id
status
qrCode
}
}
}
This represents a fairly normal set of domain objects, that sit in a database.
Our first version of the code to generate this was an all or nothing load of the graph, implementing the above query. It loads everything, and then renders it into a graph structure.
It worked perfectly for the query, and was mostly efficient. There were a few portions that issued more queries that it should, but overall, it worked, and was pretty fast!
It looked similar to this (did I mention I liked Typegraphql?):
@ObjectType()
export class HandoverRecord {
@Field()
id: string
@Field(returns => Invoice)
invoice: Invoice
@Field(returns => SiteUser)
siteUser: SiteUser
@Field(returns => BusinessTransaction)
businessTransaction: BusinessTransaction
}
@Resolver()
export class HandoverApi {
@Query(returns => HandoverRecord)
async handoverRecord(@Arg("handoverId") handoverId: string): Promise {
const handover = await handoverRepo().load(handoverId);
const invoice = await invoiceRepo().load(handover.invoiceId);
const items = await itemsRepo().load(handover.items);
const user = await userRepo().load(handover.userId);
const bt = await btRepo().load(handover.btId);
return {
items,
id: handover.id,
siteUser: user,
invoice,
businessTransaction: bt,
};
}
}
As you can see, this implements the query, and is efficient for what it is, being a well defined number of queries no matter how many, say, items, are loaded. This predictable performance is great, and something you should aim for.
Apart from that, though, it’s got some .. issues .. in extensibility.
Due to the nature of the data, it has natural relations that we modelled. Notably, businessTransaction and invoice have a bi-directional relation with each other that we found useful to have in the GQL Graph. This means the client could also send a query that looks like this:
query getHandover($btdaId: ID!) {
handoverRecord(btdaId: $ID) {
id
invoice {
currency totalAmount tax
businessTransaction {
invoices {
businessTransaction
}
}
}
}
}
This is really quite a different query, but is valid for our schema.
More likely though, the Invoice or BusinessTransaction nodes would appear in other areas of the graph. In that case, having the bidirectional relationship in place gives a great way to give context.
For this query, given its flexibility, having that relationship in place means that the implementation code above doesn’t work for this new version of the query. In fact, it actually cannot be made to work.
Moreover, the code that loads the domain objects is highly specific to this query. If we use Invoice or BusinessTransaction elsewhere, we’ll need to write the loading code again from scratch.
This diagram shows why. As soon as you have bidirectional relationships in a Graph, the naive approach above will fail as your graph building code will need to start to build arbitrarily deep graphs to satisfy the possible queries that could be made on it.
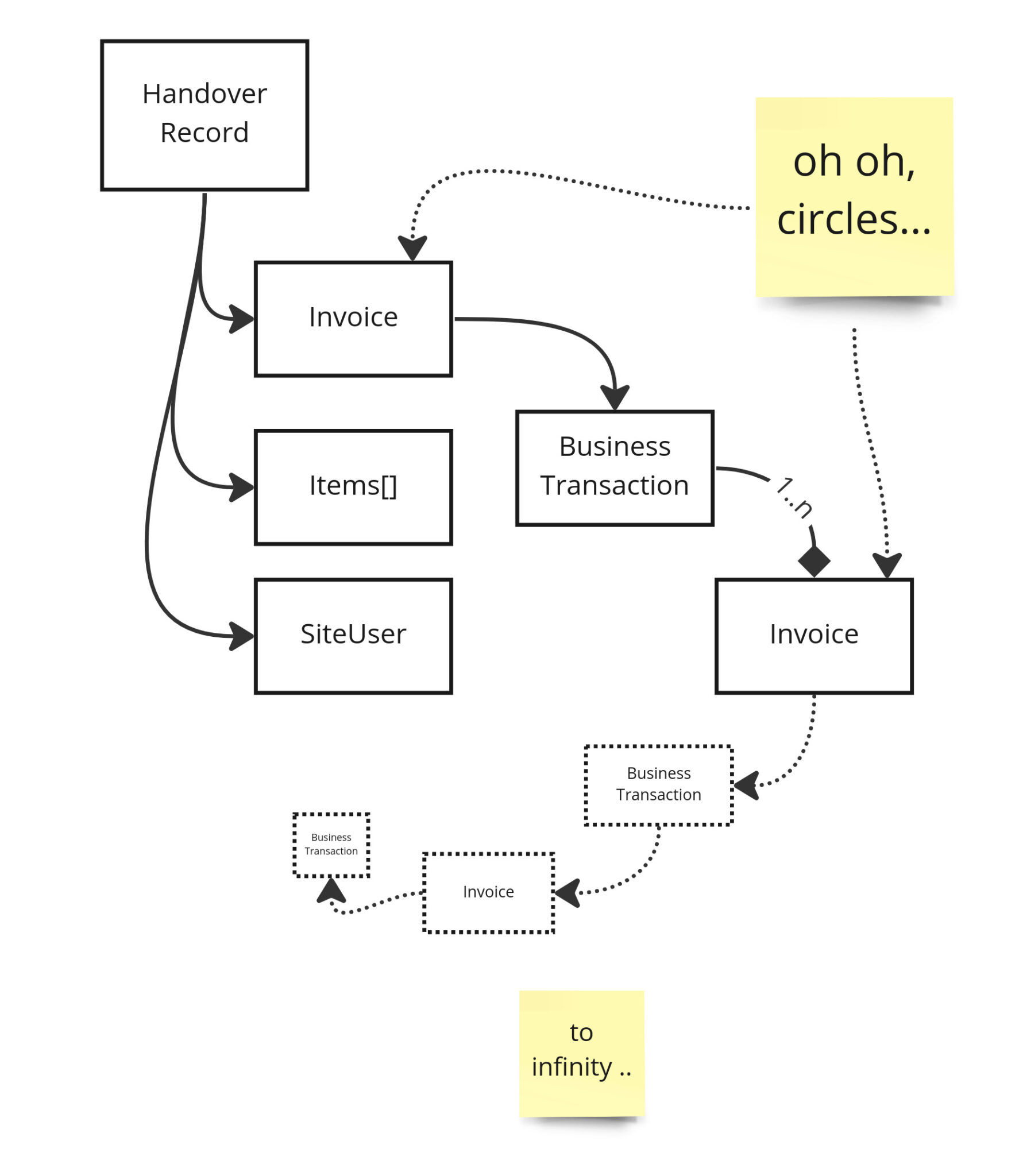
and beyond ...
This was caught when we did our code reviews and tried sending different variations on the query. When we added in handoverRecord.invoice.businessTransaction.invoice[] to the query, it went into an infinite loop and tried to batter the database to death with thousands of queries/ second.
Obviously, a bad thing.
One of the great things about GraphQL is its nature as a dynamic graph querying language. Our approach didn’t take this dynamic querying capability into account, and the results speak for themselves.
When you come to implement a GraphQL graph, you must take this into account from the start. You must also allow different parts of your graph to be queried, and for the graph query depth to be arbitrarily deep, as far as your code is concerned.
To start with, how can we allow parts of the graph to be loaded on demand? This would give us the ability to step arbitrarily deep within the graph, and hopefully let us re-use the same code for the same object.
GraphQL, and the TypeGraphql library we are using, can implement this as a kind of resolver for a type.
A field resolver allows the server to load portions of the graph only when the client requests them.
This has 2 effects we care about:
An object graph made of domain entities with bidirectional links allows you to infinitely traverse around the graph by going back and forth across the bidirectional links. This is what led to the infinite generation problem above.
A graphql client query ignores this, as it is always a tree structure. Implementing a query using a tree means that we only ever travel in one directional across a bidirectional link.
If an object appears in multiple locations in a query response, then from the clients perspective, they are different things.
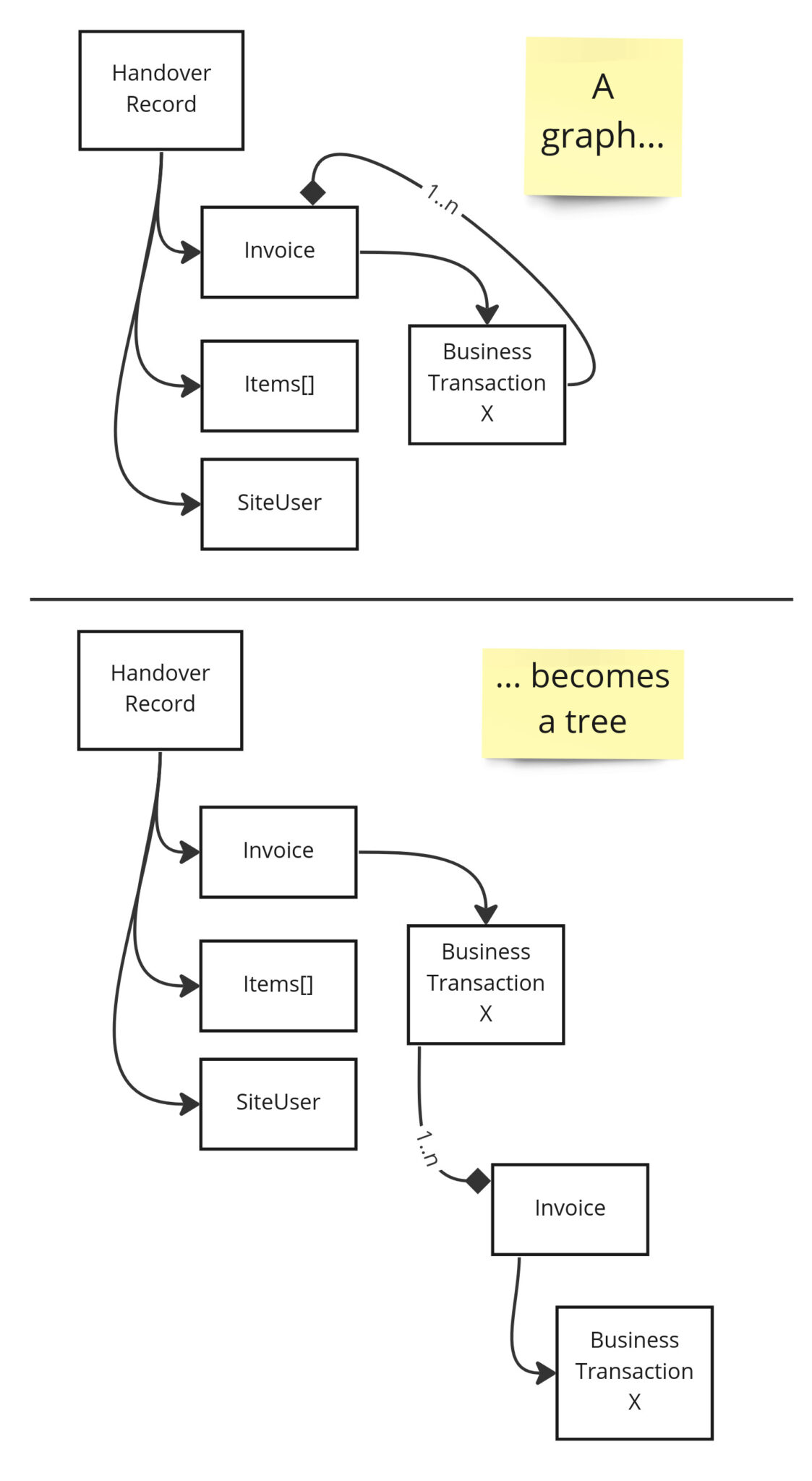
An object graph structure is always rendered as a tree when viewed in GraphQL
To adopt this approach, we would alter our original loading code to just return IDs of the entities we care about
@ObjectType()
export class HandoverRecord {
@Field()
id: string;
}
...
@Query()
async handoverRecord(@Arg("handoverId") handoverId: string) {
const handover = await handoverRepo().load(handoverId);
const ret = {
id: handover.id
} as HandoverRecord;
// this attaches the db record so the FieldResolvers can use it lower down the stack
// GQL won't allow this to be queried
(ret as any).handover = handover;
return ret
}
Above, we load the handover as before, but instead of resolving any of the other fields, we only define the ID, and then quietly attach the handover db record to the returned GQL object for use further down the stack. This is safe, as it can never be queried.
Next, create a Resolver for HandoverRecord
@Resolver(HandoverRecord)
export class HandoverResolver {
@FieldResolver()
async invoice(@Root() root: HandoverRecord) {
// this is a pessimistic load of the handover. If invoice is never requested,
// this will never execute
const handover = (root as any).handover;
const invoice = await invoiceRepo().load(handover.invoiceId);
return invoice
}
... other fields
}
Here, we’re doing the full invoice, however it’d be better like this:
@ObjectType()
export class Invoice {
@Field(returns => ID)
id: string
}
@Resolver(HandoverRecord)
export class HandoverResolver {
@FieldResolver()
async invoice(@Root() root: HandoverRecord): Promise {
const handover = (root as any).handover;
return {
id: handover.invoiceId
};
}
}
@Resolver(Invoice)
export class InvoiceResolver {
@FieldResolver()
async currency(@Root() root: Invoice): Promise {
const invoice = await invoiceRepo().load(root.id)
return invoice.currency;
}
}
The HandoverRecord resolver doesn’t concern itself with loading Invoice objects at all, only creating thin reference only objects that can then be expanded as necessary by InvoiceResolver
This allows Invoice records to appear anywhere in the graph, and this code will then load the fields as desired by the client.
By doing this, we implement a working dynamic loading approach. We can go as deep as we want on the graph, and there will be no space for infinite loading loops to appear.
We do, though have an N+1 problem …
Each invocation of a field resolver will trigger a query
This has gone from 5 queries to an unbounded number of queries. At least 20 in the case of the target query, but potentially could be much more, and importantly, this is down to the client to decide.
There is a well known technique for solving this in the world of GraphQL, DataLoaders
A DataLoader is an object that will collect IDs within a certain context, and then attempt to resolve all of the IDs as a batch. It will de-duplicate the IDs before this.
TypeGraphql can be extended with support for this technology via an NPM module
This gives a decorator that applies the approach. Adapting the Invoice resolver above, you’d get this:
@Resolver(Invoice)
export class InvoiceResolver {
@FieldResolver()
@Loader(async (ids, {}) => {
const invoices = await invoiceRepo().loadAll(ids);
return invoices.map((invoice) => invoice.currency);
})
async currency(@Root() root: Invoice) {
return (dataloader: DataLoader) => dataloader.load(root.id)
}
}
With this, no matter how many invoices we load, anywhere in the graph, this field will only ever issue a single query. Success!?
Well, no.
As you can see, this is an imperfect solution. It’s somewhat reduced the number of queries, but not as many as you’d have expected.
We no longer trigger a query every time an invoice is loaded, instead a single query is sent for all invoices. However each field has its own DataLoader, and so we load batches of Invoices from the database for each Field.
We can improve this!
At this point, we parted ways with established technology, and adapted things to make it much more efficient with a concept we called “Shared Data Loaders”.
Having a fully dynamic building of the Invoice object is a great thing, and gives many benefits, but we have to ensure that all of the field resolvers do not duplicate their calls to the database. They must somehow share their dataloaders.
Typescript decorators make this fairly easy. We took the implementation of graphql-dataloader and adapted it, creating this:
/**
* Decorator that initialises a DataLoader for a group of FieldResolvers
* Cribbed from https://github.com/slaypni/type-graphql-dataloader
*
* Will manage the lifecycle of a DataLoader around the decorated FieldResolvers.
* All requests for the field will be able to be batch loaded.
*
* Multiple FieldResolvers can use the same SharedLoader name, and will then collaborate
* with each other.
*
* A single DataLoader will be created per given name. As such, the named resolver should
* only access a single type of data that can be loaded in a single query.
*
* @see https://github.com/graphql/dataloader
*/
export function SharedLoader(
name: string,
batchLoadFn: BatchLoadFn,
options?: DataLoader.Options
): MethodAndPropDecorator {
return (
target: Object,
propertyKey: string | symbol,
descriptor?: TypedPropertyDescriptor
) => {
UseMiddleware(async ({ context, root, info }, next) => {
const serviceId = name;
const { requestId } = context._tgdContext as TgdContext;
const container = Container.of(requestId);
const arg = {
context,
info,
};
if (!container.has(serviceId)) {
container.set(
serviceId,
new DataLoader((keys) => batchLoadFn(keys, arg), options)
);
}
const dataloader = container.get(serviceId);
return await (
await next()
)(dataloader);
})(target, propertyKey);
};
}
See typegraphql-dataloader for full implementation notes.
This manages the lifecycle of a dataloader instance, however instead of attaching it to the function signature, it attaches it to a defined name. With that, we can share them between fields. The same DataLoader instance will be used on several @FieldResolver() calls, shared the requested IDs between them, and resolve them all at once.
In use, it looks like this:
// extracted loader function. Invoked only once per request.
export const invoiceLoader = async (ids: string[], arg: { context: any }) => {
return await invoiceRepo().loadAll(ids);
};
@Resolver(Invoice)
export class InvoiceResolver {
@FieldResolver(returns => GraphIntValue)
@SharedLoader("invoiceLoader", invoiceLoader) // note the well defined name
async currency(@Root() root: Invoice) {
return async (dataloader: DataLoader) => {
// block until the shared loader resolves this invoice via a bulk load
const invoice = await dataloader.load(root.id);
return invoice.currency
};
}
@FieldResolver(returns => BusinessTransaction)
@SharedLoader("invoiceLoader", invoiceLoader)
async businessTransaction(@Root() root: Invoice) {
return async (dataloader: DataLoader) => {
// block until the shared loader resolves this invoice via a bulk load
// this will return the same instance as in currency()
const invoice = await dataloader.load(root.id);
// construct a skeleton business transaction, its own Resolver will do the same as this
return {
id: invoice.businessTransactionId
}
};
}
... other fields
}
With this in place, we’re finally back to where we started, 5 queries to build the full graph.
We can arbitrarily change the requested graph in the Query, and this will adapt, and not increase the number of queries in line with the complexity.
If you reduce the complexity by not requesting particular nodes in the graph (say, SiteUser), then that resolver will never trigger, and the db call will never be made.
Wait though!
This can be further improved by applying some higher order functions as decorators
export const invoiceLoader = async (ids: string[], arg: { context: any }) => {
return await invoiceRepo().loadAll(ids);
};
const InvoiceSharedLoader = () => {
return SharedLoader("invoiceLoader", invoiceLoader);
};
@Resolver(Invoice)
export class InvoiceResolver {
@FieldResolver((returns) => GraphIntValue)
@InvoiceSharedLoader()
async currency(@Root() root: Invoice) {
return async (dataloader: DataLoader) => {
// block until the shared loader resolves this invoice via a bulk load
const invoice = await dataloader.load(root.id);
return invoice.currency;
};
}
... other fields
}
This is functionally identical to the above, but with a syntax that expresses the intent that much more clearly.
Now, we have efficient, cleanly built Graph resolvers that give us linear load on the database, extend naturally and are easily maintainable in a common pattern.
All of this also works with Apollo Federation, allows us to design and build efficient, distributed, Graphql Graphs.
Visit back soon to read up on how we do that!